
개요
AWS의 서비스를 사용해서 Serverless 워크플로우를 구성할때 Lambda만으로는 부족한 부분이 있습니다. 바로 시간이 오래걸리는 작업 혹은 다수의 로직으로 구성된 여러 Lambda의 제어입니다.
다수의 람다를 순서 혹은 로직에 따라 호출하기 위해선 SQS등의 디커플링이 필요하지만 조건적인 호출등을 구현하려면 복잡도가 증가합니다. 시간제한의 경우 Lambda의 경우 15분의 시간제한이 있고 이마저 API Gateway를 통해 호출한다면 30초로 제한시간이 줄어들지요. 따라서 이미지 프로세싱 혹은 오늘 설명할 Athena의 테이블 로딩과 같이 조금 시간이 걸리고 조건에 따라 다른 로직을 적용하는 작업의 워크플로우를 제어하는 별도의 서비스가 필요합니다. 그리고 오늘은 워크플로우 제어 기능을 제공하는 AWS Step Functions를 소개하고 Athena의 파티션 로딩을 구현하려 합니다.
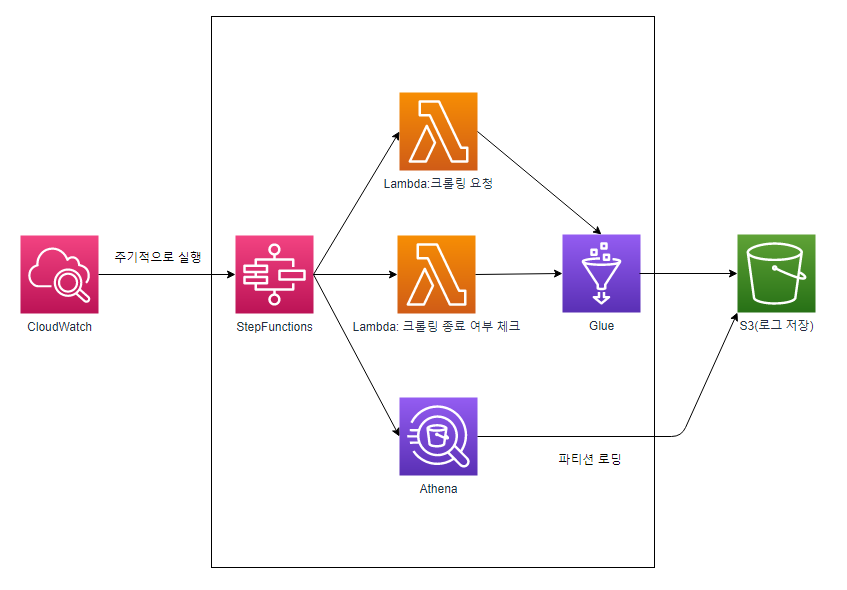
Amazon Athena, Glue와 수행내용
이번 포스팅은 Athena를 소개하는 포스트가 아니기 때문에 간단하게 Athena와 Glue를 소개하고 넘어가겠습니다.
- Amazon Athena 는 S3에 저장된 데이터를 SQL쿼리를 사용해서 조회할 수 있는 서비스입니다.
- AWS Glue 는 AWS의 ETL서비스로 다양한 기능이 있지만 이번에는 S3의에 저장된 내용을 수집하여 Athena가 쿼리를 수행할 수 있도록 스키마를 만들어주는 역할을 합니다.
현재 S3에는 어떤 어플리케이션의 로그들이 JSON형식으로 저장되어 있고 날자별로 파티션이 나뉘어 있습니다. 따라서 매일매일 새롭게 들어오는 로그에 대해 스키마를 작성하고 Athena가 쿼리 할 수있도록 파티션을 로딩해주어야 합니다. 이를 위해 CloudWatch Rule을 통해 주기적으로 Lambda를 호출하여 Glue로 스키마를 만들고 파티션을 로딩하려 합니다.

문제는 Glue가 S3의 데이터를 읽어 스키마를 생성하는 작업과 실제로 파티션을 로딩하는 작업이 상당한 시간이 걸린다는 것입니다. 데이터가 적으면 금방이겠지만 프로덕션 수준에서는 십여분 이상 걸릴 수 있는 상황입니다. 단순히 Lambda로는 타임아웃이 날 수 있지요. 이를 위해 Step Functions를 사용해보도록 하겠습니다.
AWS Step Functions
AWS Step Functions는 AWS에서 제공하는 Serverless 함수 오케스트레이터 입니다. 일종의 상태 머신으로 각 상태에 람다 혹은 AWS의 다양한 서비스의 작업을 수행하고 수행 결과에 따라 다른 상태로 도달하거나 루프를 돌 수 있는 기능을 갖추고 있습니다. 즉 다수의 람다와 AWS의 서비스로 구성된 비지니스 로직의 처리를 Serverless 환경에서 구현할 수 있도록 해줍니다.
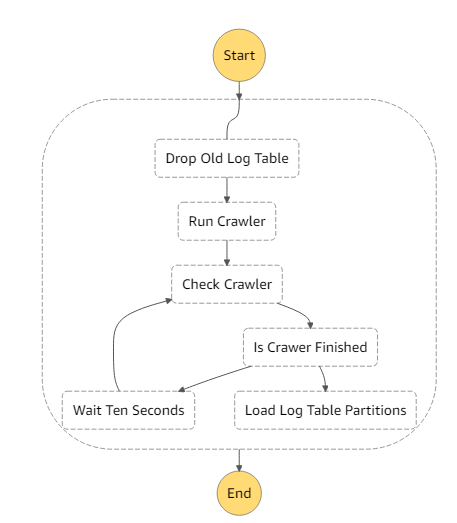
예를들면 위의 다이어그램은 [기존 테이블 삭제]->[Glue 크롤러 시작]->[크롤러 상태 점검]->[크롤러가 수행중일땐 다시 점검하고 완료된다면 파티션 로딩]의 상태로 변하는 로직을 수행하는 Step Functions의 워크플로우 다이어그램입니다. 각 상태별로 Lambda를 호출해 작업을 수행하거나 StepFunctions에서 직접 연동되있는 AWS서비스를 호출해 작업을 완료합니다. 도중에 이전 단계의 처리결과에 따라 조건문 같은 분기 처리도 가능합니다.
StepFunctions의 상태 구성은 Amazon State Language라 불리는 JSON으로 가능하며 전문은 아래와 같습니다.
1 | { |
각 상태별 설명입니다.
- [Drop Old Log Table]: 우선 기존 테이블을 “Drop Table..” 쿼리로 삭제합니다. Athena에 쿼리를 날리는것은 StepFunctions에 직접 연동되어있는 기능으로 별도의 람다를 호출할 필요가 없이 바로 수행할 수 있습니다.
- [Run Crawler]: Glue Crawler를 시작합니다. Glue Crwaler의 경우 StepFunctions에서 직접 시작할 수 없기 때문에 Lambda를 거쳐 Glue를 시작합니다.
- [Check Crawler] Glue의 현재 상태를 확인합니다.(역시 Lambda 사용) 그리고 현재 Glue의 상황을 다음 스텝으로 넘깁니다.이 때 상황은 “완료” 혹은 “진행중” 두 가지 상태입니다.
- [Is Crawer Finished]: 조건문이 포함된 상태입니다. 이전 상태에서 전달받은 Glue의 상황이 “완료”라면 다음으로 넘어가고 만약 “진행중”이라면, 4번의 60초를 기다리는 상태로 보내고 상황이 “완료”라면 5번의 Athena 테이블을 로드하는 상태로 넘어갑니다.
- [Wait Ten Seconds]: 60초를 기다리는 상태입니다. 이전 단계에서 Glue가 아직 작업을 수행하고 있을 때 넘어왔기 때문에 60초 후에 3번, 즉 Glue의 상황을 다시 점검하는 스테이지로 이동합니다.
- [Load Log Table Partitions]:4번 상태에서 Glue가 작업을 완료하면 넘어오는 단계입니다. 새로운 파티션을 로드하는 쿼리를 Athena에 직접 수행합니다.
알림이 오지 않는다?
며칠 전 Transcribe 서비스를 테스트 해 볼 일이 있어 S3 버킷을 하나 임시로 생성해서 사용하였습니다. 급하게 테스트 해볼 목적이었기 때문에 따로 태깅을 넣지 않았고 당연히 Config메세지가 슬랙으로 올 것을 기대하고 있었지만 몇 시간이 지나도 감감 무소식이었습니다. 이전에도 이런 일이 몇 차례 있었기 때문에 저는 AWS Support 티켓을 끊어서 물어보기로 했습니다. (저희 회사는 Business Plan에 가입되어 있어서 빠르게 응답을 받을 수 있습니다.)
대충 대화 내용은 이렇습니다.
- 나: AWS Config에 태깅을 검사하는 규칙을 만들어놓고 모니터링 중인데, 태깅 없이 S3 버킷을 생성해도 알람이 울리지 않는다. 벌써 1시간 반이 지났다.
- 상담원: AWS Conifg 인벤토리에 해당 버킷이 있는가?
- 나: (찾아보고) 없다.
- 상담원: 보통 몇 분 안에 인벤토리에 등록되는게 정상이다. 원인을 알아보겠다. 다른 버킷을 생성해도 그런가?
- 나: (다른 버킷을 생성 후) 방금 생성한 버킷은 잘 등록된다.
- 상담원: 흠… 해당 부서에 티켓을 끊어 자세히 알아보겠다.
- 나: 부탁한다.
그렇게 채팅은 종료되었고 해당 케이스를 좀 더 조사해보겠다고 팔로우업 이메일이 왔습니다.
갑자기 알림이 울렸다.
버킷 생성후 약 4시간 반이 지났을 무렵 갑자기 알림이 똑 하고 나타났습니다. 아예 알림이 울리지 않은것도 아니라 4시간이나 딜레이 되었다는 것이 이 사건을 더욱 아리송하게 만들었습니다.

며칠 후 답변이 오다.
바쁜 일정에 잊고 지낸 며칠이 지난 후, 장문의 답장이 아래처럼 도착했습니다.내용 하나하나가 중요하기에 전문을 인용하겠습니다.
(몇 가지 식별 정보만 “-“로 처리하였습니다.)
To understand why the Config service was not able to discover the resource, it is important to know that Config relies on CloudTrail logs to log/discover new resources. If, for example, the ‘CreateBucket’ API call is called when you create a new bucket, this API call will be realised by the config service to discover and log the resource in it’s inventory.
Now in situations, when the API call is not generated/not-detected from cloud-trail end, Config will try to make Get*, Describe* and List* calls on the resources to detect these missed CI’s (Configuration items). These checks are made at a periodic interval and then the resources are discovered after updating their CI’s.
After understanding the process, let us now try to understand what happened in your situation. When you created the bucket: “twinny-rnd-transribe”, an API call ‘CreateBucket’ was detected in the ‘us-east-1’ region. Here’s the API call for your reference:
{
“eventVersion”: “1.08”,
“userIdentity”: {
“type”: “IAMUser”,
“principalId”: “-“,
“arn”: “arn:aws:iam::-:user/twinny-rnd-spark-s3”,
“accountId”: “-“,
“accessKeyId”: “AKIAIGEUYE2L5HG4JG3Q”,
“userName”: “twinny-rnd-spark-s3”
},
“eventTime”: “2021-02-26T08:01:03Z”,
“eventSource”: “s3.amazonaws.com”,
“eventName”: “CreateBucket”,
“awsRegion”: “us-east-1”,
“requestParameters”: {
“CreateBucketConfiguration”: {
“LocationConstraint”: “ap-northeast-2”
},
“bucketName”: “twinny-rnd-transribe”,
“Host”: “s3.amazonaws.com”
},
“responseElements”: null,
“eventID”: “3a158e73-fd32-4247-9388-31bde5fcf30a”,
“recipientAccountId”: “-“
}Note: I have redacted a few components for clarity. You can refer to the eventID to search the log at your end. You can follow this document to understand how the logs are filtered using CloudTrail filter [1].
From the call you can see that the event was run from the region - us-east-1, but with the location constraint parameter in the ‘ap-northeast-2’ region you have essentially made an API call from the us-east-1 region to create a bucket in the ‘ap-northeast-2’ region.
Now, since you have your config recorder enabled only in the “ap-northeast-2” region, Config would not be able to analyse the CloudTrail API’s that happen in any other region. Hence, this API was not realised by the Config service initially due to which your bucket was not discovered. If you observe, all the other ‘CreateBucket’ API’s for other buckets have been made in the “ap-northeast-2” region due to which the other buckets were automatically discovered.
For the “twinny-rnd-transribe” bucket, when later config tried to make an automatic sweep for the missed CI, it tried the read API calls on all the resources in the ‘ap-northeast-2’ region, which it was able to detect successfully, and hence it was recorded in it’s resource inventory. Please note that this automatic sweep happens periodically in intervals happening once every day, with the timing not being fixed.
대략 정리하면 이렇습니다.
- AWS Config는 내부적으로 CloudTrail Log를 참조하여 동작한다. 즉 S3라면 “S3:CreateBucket” API 로그를 참조하여 새 버킷이 생성된 것을 파악하고 Get*, Describe* and List* 등을 사용해서 나머지 상태를 파악한다.
- 그런데 이슈가 되는 버킷 “twinny-rnd-transribe”의 API는 us-east-1로 API가 전달되었다. (S3 Browser라는 프로그램을 썼습니다.)
- 즉 나(필자)는 ap-northeast-2에 버킷을 생성해달라는 API를 us-east-1리전에 날렸다.
- 그리고 AWS Config가 ap-northeast-2 리전에만 적용되어 있기 때문에 ap-northeast-2 리전의 Config는 us-east-1의 CloudTrail Log에 기록된 버킷 생성 로그를 발견하지 못하였다. 그래서 처음에 바로 알람이 울리지 않았다.
- AWS Config는 자체적으로 놓친 내용들을 검토하기 위해 설정된 리전의 모든 리소스와 관련된 API를 훑어보는데, 이 과정에서 놓쳤던 버킷을 발견하여 알람을 발생시켰다. 이 훑어보는 교정작업은 하루에 한번정도 이루어지며 시간은 딱히 명시되지는 않는다.
결론
결국 언젠가 규칙 평가가 이루어지긴 하지만 AWS Config가 설정되지 않은 다른 리전에서 생성을 요청한 리소스는 규칙 평가가 늦어질 수도 있습니다.
경험적으로 AWS Config가 바로바로 규칙 평가를 하지 않는 사건은 몇 차례 있었지만, 그 원인을 이번에서야 명확하게 알게 되었습니다. 혹시라도 같은 궁금증을 품고 계셨을 데브옵스 엔지니어 분들께 도움이 되었으면 좋겠습니다.